2010-03-07
Parallel Programming with OpenMP
 The geek-chic OpenMP logo.
The geek-chic OpenMP logo.
This is a brief intro to using OpenMP for parallel programming (with what I've discovered about it so far). We'll implement a Mandelbrot Set renderer that runs multicore, and throw in a couple aside-goodies as well (basic supersampling and Mandelbrot continuous coloring).
First, let's talk parallel programming. The basic idea here is that we have some task that can be split up into parts, and we hand off each of these parts to different CPUs.
A real-life example might be this: you have a pile of 1000 envelopes that all need to be opened. If you are by yourself, you just open one at a time until you are done. But if you bribe your friend with pizza, he might come over to help you. In that case, you split the envelopes into two piles, and both of you open them until you've each done 500, and then you are done. It takes half the time. Or, if you invite 10 friends over to open 100 envelopes each, it takes one-tenth the time.
Problems like this which parallelize easily are called embarrassingly parallel problems. You throw \(N\) CPUs at the problem, and the time it takes to finish is divided by ((N\). (Practically speaking, you won't actually get that linear speedup. See Amdahl's Law.)
Of course, it's not always that easy, at all. For example, if you are baking cookies at home, you can invite 40 friends over, but the cookies won't be done baking in a much shorter time (a little bit shorter, perhaps, as you can delegate a few minor tasks in the process, but certainly not 40-times shorter). It doesn't matter if someone is ready to put the tray in the oven if the cookie dough isn't done being made! Most people will be standing around idle most of the time.
(Actually eating the cookies once they're baked, however, is an embarrassingly parallel problem, and your 40 friends will make short work of 40 of them in the same time it takes you to eat just one!)
It's the same with CPUs, except there are fewer cookies involved.
Now, there are many many ways of writing software that executes in parallel, and which way you choose really depends on t he problem domain. OpenMP is, from what I can tell, a fine choice for non-distributed programs that need to use more cores for, say, number crunching. Some other locally-running programs might be better suited to use something like a thread pool. OpenMP is just one option, but it can be appealing due to its ease-of-use.
For this demo, we'll be looking at a Mandelbrot Set rendering program. You can read my other post on how the Mandelbrot Set works, but the relevant recap is that we're going to process each pixel of the image by running it through an algorithm to determine its color based on its position on the screen.
Each pixel is rendered independently of each other pixel, and it doesn't matter in which order they're processed; there are no data dependencies—it is embarrassingly parallel. We should be able to hand off pixels, or groups of pixels to each CPU and have them run at the same time, and get a speedup somewhat proportional to the number of CPUs that are put to work. (Time to use that quadcore of yours for something!)
For this, the OpenMP API can really help make it easy to write parallel programs. Instead of spawning a thread, you tell the compiler which sections of code can be made parallel, and optionally tell it which variables can be shared between threads, which need to be private, and tons and tons of other optional stuff (OpenMP is featureful), and the compiler generates the right code for you.
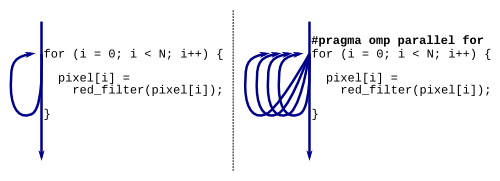 Single-threaded execution of a for-loop vs. multi-threaded execution on
four cores via OpenMP with the "omp"
Single-threaded execution of a for-loop vs. multi-threaded execution on
four cores via OpenMP with the "omp" #pragma. Note that in this
for-loop, each thread operates on its own pieces of data without
overlapping other threads... via the magic of OpenMP.
Here's a non-parallel regular-old-run-of-the-mill standard example that will multiply every element in an array by 2 in C:
int i;
int a[10] = {3,6,3,1,7,9,5,6,9,1};
for (i = 0; i < 10; i++) {
a[i] *= 2;
}
Normal enough, right? And you can see that it can be easily parallelized by letting different CPUs work on different parts of the code.
Now here's the OpenMP variant:
int i; int a[10] = {3,6,3,1,7,9,5,6,9,1};
#pragma omp parallel for
for (i = 0; i < 10; i++) {
a[i] *= 2;
}
Tada! That is it! With that one pragma, the for-loop will now execute in parallel on all cores. (Assuming your compiler supports it!)
You'll probably also have to tell your compiler to use OpenMP:
- gcc: Pass the
-fopenmpswitch on the command line.- Visual Studio: Edit the project and add the
/openmpswitch.- XCode: Edit the project and select at least GCC 4.2 or LLVM GCC 4.2. Check the "Use OpenMP" box.
- For other compilers, search Google for your compiler and "openmp" and see what comes up.
And with that, I have to admit that I might have glossed over (just a tad) some of the incredible number of minute intricacies of multithreaded programming. The Devil is, naturally, in the details, and problems are rarely as simple as this. OpenMP has a wide variety of directives to help you through your multi-threading needs, but it really is possible to get yourself into trouble with race conditions and deadlock so on.
Here's a bad example (please ignore how contrived it is):
int i, j;
int a[10] = {3,6,3,1,7,9,5,6,9,1};
#pragma omp parallel for
for (i = 0; i < 10; i++) {
// BADNESS! race condition in here:
j = a[i];
j *= 2;
a[i] = j;
}
It's the same as before, except we've put the value in a temp variable
j to multiply by two before transferring it back.
So what's the problem? The problem is that Thread A might set j to
a[2] (which is 3), then Thread B sets j to a[5] (which is 9). And
then Thread A multiplies j by 2, and comes up with 18 when it should
have come up with 6, and happily and wrongly stores 18 in a[2].
The problem is that both threads are using j at the same time and
stepping on each others' toes. They each need their own private version
of j so it doesn't conflict with other threads. They can do it like
this:
int i, j;
int a[10] = {3,6,3,1,7,9,5,6,9,1};
#pragma omp parallel for private(j)
for (i = 0; i < 10; i++) {
j = a[i];
j *= 2;
a[i] = j;
}
And now they each get their own copy of j to mess with.
Another option to do the same thing is to declare j to be local to the
block—this makes it automatically private:
int i;
int a[10] = {3,6,3,1,7,9,5,6,9,1};
#pragma omp parallel for
for (i = 0; i < 10; i++) {
int j; // j is private because it's block-local
j = a[i];
j *= 2;
a[i] = j;
}
With that in mind, let's think about my OpenMP Mandelbrot renderer: goatbrot (with source on github). This thing is going to generate a color for each pixel of the image, and it's going to write the result out in a file.
I've run this program on Linux and OSX. It should run on any Unix-like. Modifications will need to be made to get it to build for Windows—these mods are noted in the README.
For this program, the output is written in PPM (Portable Pixmap Format), a venerable format used since the olden days by the Netpbm library. It consists of a very simple header followed by uncompressed RGB triplets, each channel stored as an 8-bit unsigned value. So 3 bytes per pixel, then.
Search for Netpbm for your platform if you don't have something that can view these images already. Mac users can get it from MacPorts.
Or you might already have the
cjpegtool for creating JPEGs.Conversion to PNG or JPEG can be done on the command line like this:
$ goatbrot -o foo.ppm $ pnmtopng -compression=9 < foo.ppm > foo.pngor
$ goatbrot -o foo.ppm $ cjpeg -quality 85 < foo.ppm > foo.jpgFor the curious, I selected this output format because it's dead-simple, and doesn't introduce any more library dependencies on the code.
A couple more notes:
The quickest way to a pretty render is with the
-eswitch to choose an example render (1 through 8):goatbrot -e 3 -o foo.ppmGive the
-hswitch for usage informationGive the
-tswitch to choose the number of threads—default is the number of cores you have availableThe
-uoption gives continuous coloring, and the-aoption does simple anti-aliasingThere's some theme support hastily hacked in there, too
So it'll loop through the row and columns as normal, except we'll stick
a #pragma omp before the loop so that it runs in parallel, and we'll
put all the thread-local variables inside the block so they'll be
private per-thread. Here's that snippet:
#pragma omp parallel for
for (y = 0; y < height; y++) {
// declare thread-local variables in block here
for (x = 0; x < width; y++) {
// do heavy mandlebrot lifting
// write output
}
}
So that'll start a bunch of thread on a per-row basis. (That is, it's
the row-oriented loop over variable y that's being parallelized—the
inner loop is not.)
I did an experiment and tried putting the
#pragma ompin front of the inner loop (which would parallelize on a per-pixel basis, instead of a per-row basis), and it slowed down the run considerably. I didn't pursue it, but I figure it's because the thread overhead is high compared to the cost of producing a pixel, but low compared to the cost of producing a row of pixels.But since there are likely to be more rows in the image than you have cores at your disposal, it's just fine to parallelize on rows.
Now it's time to notice another wrench in the works, already shown above
in the comment "write output". What happens to this output when we
have a bunch of threads trying to write it at the same time?
Here's the short answer: Bad Things.
OpenMP doesn't make any statement about I/O, and leaves it all up to the programmer. (It's a rather sane stance, I think.) And that means it's all up to us!
We could try to force all the threads to write the data in order, but that sounds like 1) a pain, and 2) a great way to slow things back down again. It would be better if we could somehow allow all the threads to write the data out to disk at the same time.
But this means they either have to write to different files, or all somehow have random access to the same file.
I chose to implement the latter for this demo, giving all threads random access to the same file. Since none of the threads are going to be overwriting each other's data, I don't have to lock the file, either. How do we get that kind of random access to a file?
We can use something called a memory-mapped file. This is a file that
has been mapped into memory and looks for all intents and purposes like
a big array. The first step is making a file big enough to hold all the
data (which I did with Unix's ftruncate()
syscall). The next step is
to memory-map the file, and get a pointer to the data (using the
mmap() syscall).
Once we have a pointer to the data, we just calculate the relative
offset to the base pointer, and memcpy() the data into place.
What are we giving up? Well, as any good Unix geek will tell you, pipelines make the world go around. A common MO with Netpbm tools is to pipe on command into another, like this command to scale a JPEG image down and convert it to a grayscale PNG:
djpeg example.jpg | pnmscale -xysize 400 400 | \ ppmtopgm | pnmtopng > output.pngAnd the problem is that if we're writing to the file in different places from different threads, you can't linearly write it out. That is, threads that are rendering the end of the image might finish before threads that are rendering the beginning of the image. (Of course, you could save the file to a temp file, and then copy it to standard output when you're done. Since some of the files produced by this program could be huge, I decided not to do that behind the users' backs, but it's a matter of preference.)
Another option that occurred to me was to write out each thread's data to a different file. The records in these files could have the row number prepended to each bit of pixel data. Then at the end of the run, the program could merge those records into the final image.
Finally, I feel like I should mention there could be a way to use the
#pragma omp orderedconstruct to force the writing of the data to happen in the same order as the loop. However, I was unable to get this to work in such a way that the CPU load was properly distributed—most of the threads just stayed idle. I have more exploration to do there to figure it out.
So anyway! One more thing I can mention is that OpenMP provides ways
to control execution through sections where only one thread should be
running at once—such areas are known as critical
sections. In the
Mandelbrot program, I output a progress meter that shows the percentage
complete. And rather than having all threads just output whenever, I
wrap that up in a #pragma omp critical construct—this forces that
section to be executed by only one thread at a time.
A graph showing some relative runtimes for multiple threads:
 Relative runtimes of the
Mandelbrot renderer for various processors. Lower is faster/better.
Notice that the hyperthreaded single core Atom gets an improvement with
two threads, but it's not a two-fold improvement. The genuine dual-core
processor actually halves its runtime. And the single-core Athlon 64 is
nothing if not consistent. (And because I know you're curious, the
actual fastest-of-all runtimes from these three systems were 16 seconds,
41 seconds, and 5 seconds, respectively, for what it's worth, which
ain't much—remember it takes all kinds of things to make a system, and
those things all influence end-performance.
Relative runtimes of the
Mandelbrot renderer for various processors. Lower is faster/better.
Notice that the hyperthreaded single core Atom gets an improvement with
two threads, but it's not a two-fold improvement. The genuine dual-core
processor actually halves its runtime. And the single-core Athlon 64 is
nothing if not consistent. (And because I know you're curious, the
actual fastest-of-all runtimes from these three systems were 16 seconds,
41 seconds, and 5 seconds, respectively, for what it's worth, which
ain't much—remember it takes all kinds of things to make a system, and
those things all influence end-performance.
(What's with the funky high runtimes with odd numbers of threads? I don't know for sure, but my reading around the web seems to indicate something to do with caching and/or scheduling. The Atom is running Linux and the Duo is running OSX. Any ideas?)
So, there's way more to OpenMP than I've mentioned here—it's a pretty big system with lots of features. But, like I've shown, it can be a really quick way to rip into embarrassingly parallel problems.
More info: