2012-02-19
Minimax
 Some moves are better than
others. (This image represents my maximum drawing ability; I've titled
it "The Unfeeling Mustache Of Justice".)
Some moves are better than
others. (This image represents my maximum drawing ability; I've titled
it "The Unfeeling Mustache Of Justice".)
It's time for me to once again blog about something I barely know anything about: using minimax for game AI! Game on!
Let's say you have a game, like tic-tac-toe, where each player makes alternating moves. When you make your move, you're thinking, "Where is my opponent going to move after this? And what move will I make then?" And your opponent is thinking the same thing.
Each step of the way, you assume your opponent is going to do what's best for them and worst for you. (Maybe they'll make a mistake, and you'll get an advantage, but don't count on it.) And every step of that look-ahead that you both are doing, you both are thinking, "What move should I make that minimizes my loss and maximizes my gain?"
There is a groovy little algorithm that works well for this type of game: the minimax algorithm.
With minimax, what I'm going to do at each look-ahead stage is decide my move based on what minimizes my loss (and therefore maximizes my gain, and maximizes your loss and minimizes your gain.) And you're going to do the same thing. We both want to minimize our maximum loss.
People look ahead, they build a little tree in their heads about different paths to follow. Computers can do the same thing, too. What we'll do is start with the current state of the board as the root of the tree, and the children of the root will be potential board positions one move from now. For instance, if it's X's turn to play, the child nodes of the root will represent all possible legal moves for X.
We build out the look-ahead tree for several alternating turns. Each level of the tree in this case is referred to as a ply. Each ply contains the number of nodes that is equal to the number of legal moves at that point... so if there are large numbers of legal moves, the number of children and grandchildren can grow really frickin' fast.
Let's have a look at a game of tic-tac-toe in progress:
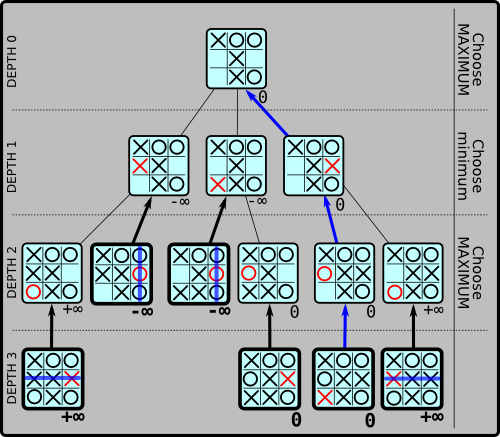 A tree representing future
possibilities in a game of tic-tac-toe. It's X's turn. The root node is
the current state of the board, and children represent future moves.
Moves taken are shown in red. Bold nodes are leaf nodes. Bold arrows
represent node values chosen from child nodes at each ply. The blue
route is the best path for both players to minimize both their losses,
and is how the game will progress with perfect play by both
parties.
A tree representing future
possibilities in a game of tic-tac-toe. It's X's turn. The root node is
the current state of the board, and children represent future moves.
Moves taken are shown in red. Bold nodes are leaf nodes. Bold arrows
represent node values chosen from child nodes at each ply. The blue
route is the best path for both players to minimize both their losses,
and is how the game will progress with perfect play by both
parties.
To read the above graph, take it in several phases. First of all, completely ignore the numbers (the node values). Just see how the tree is built out showing possible future board positions. (At this point, so late in the game, it's possible for me to show all future positions of this board.)
The current turn is at the root node, and X has three possible moves. These are shown in the next level down. Then, on that level, it would be O's turn, and all possible subsequent board configurations are shown as children of the next level down.
The bold nodes are the leaf nodes, where no further exploration is possible because the game is over, ending in either a draw, or with a single victor.
Got it?
Ok, phase two: the numbers. This time, just look at the leaf nodes.
Each leaf node is going to be assigned a score. In this case, we'll assign a score of zero for a tie game, positive infinity for a win by the current player (X), and negative infinity for a loss by the current player.
Basically what we've done is described how desirable a particular board position is for the current player. (E.g. if the board position shows your opponent basking in glorious victory, you'll rate that with desirability "negative infinity".) But more than this, we've determined: if the game reaches this board position, the number at that position tells us the best we can possibly do if our opponent plays perfectly from that point.
Got it? We're about to have some big fun. (It's important to remember throughout this process that we're not actually playing the game out; we're pretending to play games, speculatively, by running around on the look-ahead tree.)
Phase three: Go back up a level from the bottom to "DEPTH 2". Let's see whose turn it is... it looks like it would be X's turn to play at this point. X wants to play to whichever node has the highest value. So what he'll do is mark nodes at DEPTH 2 with whatever the maximum value of that node's children is. (Because it would be X's turn at this point, being at the current node is just as good as being at its child node with the highest value—X would just move there immediately.)
(Admittedly this isn't very exciting at this point, because each node at depth 2 only has at most one child, so there's not much choosing.)
Ok, so after we've assigned values to all nodes at depth 2, let's keep going up to "DEPTH 1". At this depth, it would be O's turn. Now O, with her long-running multi-generational feud with X, would be eager to choose whichever node is the WORST for X, i.e. the node with the minimum value for X. So if a node at depth 1 has one child with value +∞ and another child with value -∞, O will be moving to the -∞ child. So since it would be O's turn at this point, she marks the current node's value to -∞, as well.
Then backing up to "DEPTH 0", it's X's turn. Now X looks at the possible moves below, and he sees that two of O's are rated -∞, while one is rated zero. What this means to X is that if he moves to a board rated -∞, he will absolutely positively lose (barring any mistakes by his opponent, and assuming the look-ahead tree exhausts all possible future board positions). So like always, he's going to choose the child node with the maximum value, in this case zero.
And the child node with the highest value at depth 0 is the move the current player should make! Voila!
Again, put another way, the current player looks at the children of the root node, and he sees that two of them are rated -∞, i.e. a sure loss. This is the best he can expect to do if he plays either of those nodes, assuming no mistakes on his opponent's part. So instead of playing the sure loss, he plays the better move with higher value zero (which leads to a sure draw.)
Keep this in mind: we've gone through the tree above in a very human-like manner. Computers are far more likely to use recursion to process the tree structure. Notice that every node is given the minimax value of its own subtree, so there's the self-similarity for a recursive procedure. Plus there's more self-similarity in building the move tree downward from the root.
Some pseudocode that behaves this way:
var active_player # the real active player this turn
var game_board # the board being played this turn
var best_move # will hold the best move after minimax()
procedure computer_move():
# the following function eventually sets the best_move global
minimax(game_board, active_player)
make_move(game_board, best_move, active_player)
procedure minimax(board, curplayer):
minimax_recurse(board, curplayer, 0)
procedure minimax_recurse(board, player, depth):
# if maxed out, return the node heuristic value
if depth > MAX_DEPTH:
return find_node_heuristic_value(board, player)
# see if there's a winner
winner = is_winner(board)
if winner == active_player:
return INFINITY # active player wins!
else if winner != NONE:
return -INFINITY # active player loses
else if no_more_moves(board):
return 0 # tie game!
# figure who the other player is:_
if player == PLAYER_1: other_player = PLAYER_2
else: other_player = PLAYER_1
# init alpha with this starting node's value. The current player
# will raise this value; the other player will lower it.
if player == active_player:
alpha = -INFINITY
else:
alpha = +INFINITY
# get a list of potential moves this turn:
movelist = get_move_list(board)
# for all those moves, make a speculative copy of this board
for move in movelist:
board2 = copy_board(board)
make_move(board2, move, player)
# and recurse down to find the alpha value of the subtree!
subalpha = minimax_recurse(board2, other_player, depth + 1)
# If we're the current player, we want the maximum valued
# node from all the child nodes. If we're the opponent
# we want the minimum:
if player == active_player:
# if we're at the root, remember the best move
if depth == 0 and alpha <= subalpha:
best_move = move
alpha = max(alpha, subalpha) # push alpha up (maximize)
else:
alpha = min(alpha, subalpha) # push alpha down (minimize)
# finally, return this subtree's value to its parent:
return alpha
One possible mod to the above, is to make a list of equally best moves and choose randomly out of them. Or maybe even mix in some moves that are good, but aren't the best, just to liven it up a bit.
Above, when I said that X will absolutely positively lose on certain moves, it means that he'll lose to the best of his knowledge, depending on how many plies down the tree he has looked. In the case of the example, we looked ahead all the way to the end of the game, so he was, in fact, completely sure.
But what if we can't look down the tree that far? I mean, tic-tac-toe is a pretty simple game, and there are only 9 possible moves to start, and only 9 total moves in an entire game. (Nevertheless, it gets big fast; depth 1 has 9 nodes, depth 2 has 72 nodes, depth 3 has 504 nodes, etc., not counting symmetry and ended games.) Compare that to something like chess, which has tons of possible moves; the tree gets unmanageable huge in a short time.
Modern chess computers will dig down around 10 plies, or maybe lots more in certain circumstances. But that's not enough to get you to the end of the game, right? Maybe not even close to the end!
How do you rate the value of a move if you can't see that it is a win, loss, or draw? What you do is write a heuristic function that rates the board based on other things. Perhaps a particular position leaves the player with the center of the board well-controlled, so that should be rated more highly than a board position that leaves the player crowded out to the edges.
If you get close to the end of the game, and the computer has run the tree out to the end (like we did with tic-tac-toe up there), and it finds a move rated +∞, then it can be absolutely positively sure it will win in that many moves.
And it can tell you so. "Checkmate in 4! No matter what you do! Skynet R0olZ!"
One shortcut humans can take when they are building their tree is to recognize that certain moves are just going to be bad and not bother speculating down that branch of the tree any more. This has the advantage of keeping the tree down to a more reasonable size.
Computers have the same needs. Having a smaller tree allows it to fit in memory, plus saves on processing time required to explore it. One historically popular technique for doing this is a technique called alpha-beta pruning. (Though apparently NegaScout outperforms it, I haven't implemented either, and alpha-beta looks like a better starting point if you're going to look into it for learning purposes.)
Also sometimes boards have repeated positions or symmetry you can exploit to keep the size of the tree down.
What about an implementation? For a twist, I'll give you a tic-tac-toe player (written in Python), that uses the negamax variant of minimax. It's basically the same thing, except the code is slightly cleaner, but it only works for zero-sum games.
A zero-sum game is the sort of game where your loss is exactly equal to my gain, and vice-versa. This is important because later on when we’re analyzing moves of the game, if you see that in a particular move I earned 20 points, you’ll know that’s the same as if you’d lost 20 points. In a way, this enables you to rank my moves in the same manner that you rank your own. Negamax takes advantage of this.
So here's that tic-tac-toe code! Note that it dives down 6 plies, which is enough to make it play smartly because it can see when the wins start to occur. There is no heuristic function of substance for the leaf nodes; if it's a win, it's scored to the properly-signed infinity, else it's zero. So reduce the max depth, and you'll see it starting to make some poor decisions.
A funny aside is that the AI doesn't track how soon a victory will occur for a particular move. That is, if it knows that any of moves [1,3,5] will eventually win, it will choose one at random, regardless of whether it leads to a win immediately, or in two moves. This can sometimes lead to the impression that the AI is prolonging your agonizing defeat, instead of just mercifully ending the game.
Code disclaimer: the code is written for clarity, not for speed. So there are plenty of places where it's just plain slower than it has to be. And a minimax algorithm doesn't produce the fastest perfect tic-tac-toe AI.