2010-01-19
Digital Sound
 A human listens to Mozart's
Violin Concerto No.
3. Either that or it's "Ace of Spades" by Motörhead.
A human listens to Mozart's
Violin Concerto No.
3. Either that or it's "Ace of Spades" by Motörhead.
Let me start off by saying, "Don't do any of this yourself." This is one of those topics where there are countless libraries already written for you with well-designed and well-tested code to do everything you want and more. It's presented here because it fits criterion #1 for why you'd re-invent the wheel: you're doing it because you want to learn more about it. So there you have it!
There are many ways to represent sound digitally, but let's start with sound in real life. The situation we have is that a bunch of alternating high- and low-pressure waves are moving through the air like ripples in a pond. They reach your ear and push your eardrum in and out. The eardrum's connected to the what's-it, the what's-it's connected to the thing-a-ma-bob, and the thing-a-ma-bob is connected to your brain, which fools you into believing you're hearing something, depending on how your eardrum is moving.
The closer together the pressure waves appear (that is, the faster your eardrums get moved back and forth), the higher the pitch you hear. The taller the pressure waves (that is, the farther your eardrums get moved back and forth) , the louder you hear it.
The number of waves (or "cycles") that go by every second is called the "frequency", and is measured in cycles-per-second, also known as hertz, abbreviated as Hz. "Concert A" is 440 Hz, or 440 cycles per second.
If we were to build a sensitive air pressure monitor that would output a particular voltage depending on how big the pressure wave was at any instant in time, we would have what those in the industry call "a microphone". If we were to take those electrical signals and store them on an analog tape, we'd have a tape recording. If we then read those signals from the tape, amplified them, and ran the resulting power through a coil of wire wrapped around a floating magnet connected to a diaphragm which could push waves of air, we'd have a speaker. When those waves of air reaches your ear drums, you'd hear how weird you actually sound to everyone else.
Enough of this "real life" stuff—how do we get all digital?
Let's start with the real life wave we have. Imagine the pressure waves are arriving at a sensor, and the sensor is telling us that the wave pressure is going back and forth between 0.8 and -0.8 units. (What is a "unit"? Well, I'm going to leave that a little bit vague for the moment. Let's just pretend that your speakers can go from -1.0 to 1.0 before they start cutting out, so -0.8 to 0.8 is within your pretend speakers' tolerances.) Furthermore, we'll say the wave shape is a nice sine wave, though this is rarely true in nature.
How do we take this nice mathematically perfectly smooth sine wave and turn it into something the computer can understand? Well, we sample it. That is, we periodically grab the value of the wave at some instant and we store it. And then we wait a very short time and grab the value again and store it. Values between these times are simply lost.
A very common way (though certainly not the only way) of saving these values is called Pulse Code Modulation (PCM). You chose a rate that you'll sample at, say 44,100 samples per second, and so you grab a sample every 1/44100th of a second and store it.
In the following diagram, you see the original "real" sound wave in blue, with the sample points and their values in black:
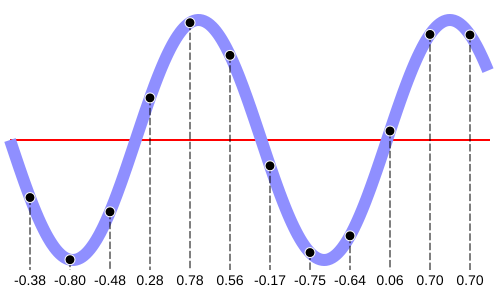 Original wave in blue, with sample
points and values (ranging from -1 to 1) in black.
Original wave in blue, with sample
points and values (ranging from -1 to 1) in black.
When you want to play back the sound, you read the samples, and you reconstruct the original wave as best you can. And that is a process which, as Canar points out in the comments, is stellarly performed by your digital-to-analog converter.
How do we actually store those levels? It's usually mapped to an integer value that can be represented by some number of bits, often 8 or 16. Sometimes it's signed, and sometimes it's unsigned; it depends on the format in which its stored. All that really matters is that your sound player knows the format so it can decode it and try to reconstruct the original real-life waveform.
Here's some C code that maps numbers in the range \([-1.0,1.0]\) to \([-32768,32767]\), which fits in a 16-bit signed number:
int remap_level_to_signed_16_bit(float v)
{
long r;
// clamp values:
if (v > 1.0) { v = 1.0; }
else if (v < -1.0) { v = -1.0; }
v += 1.0; // remap from [-1.0,1.0] to [0.0,2.0]
v /= 2; // remap from [0.0,2.0] to [0.0,1.0]
r = v * 65535; // remap from [0.0,1.0] to [0,65535]
return r - 32768; // remap from [0,65535] to [-32768,32767]
}
(I could have rolled all that into one expression, but sometimes it's useful to see how the ranges get remapped.)
What does a CD store music as? It uses PCM, and samples at 44,100 samples per second, which is sometimes written as 44,100 Hz or 44.1 kHz (but it's the sample rate, not to be confused with frequency of the sounds.) It stores those samples as signed 16-bit numbers that range from -32768 to 32767. Anything louder than that is clipped to those levels.
Why was 44,100 Hz chosen as the sample rate? The short answer is that we need to sample at more than twice our maximum representable frequency to avoid aliasing problems, and humans can hear tones up to frequencies around 20,000 Hz. So we double that with some for good measure, and get to 44,100 samples per second. The long answer is wrapped up in something called the Nyquist Frequency.
What about generating these sounds? What if we wanted to fill a buffer with sampled sound data? You have to figure out what frequency you want to generate, what shape the wave should be, what sampling rate you want to use, and how to store the samples, and what volume the sound should be. Here's a way to generate a 440 Hz tone with a sine wave for one second, sampled at 22,000 samples per second, stored as 16-bit signed data:
// assume buffer has 22000 elements in it to hold all the data:
void generate_440(int *buffer)
{
int pos; // sample number we're on
float volume = 0.5; // 0 to 1.0, one being the loudest
// 22,000 samples per second for one second = 22,000 samples total:
for (pos = 0; pos < 22000; pos++) {
// we need to remap from our sample position to a wave that
// cycles at 440 Hz. Each cycle on a sine wave's domain goes from 0
// to 2 * PI, and we're going to do that 440 times in 22000 samples
// or 1 time in 22000/440 samples:
float a = (2*3.14159) * pos / (22000 / 440.0);
float v = sin(a) * volume;
// convert from [-1.0,1.0] to [-32768,32767]:
buffer[pos] = remap_level_to_signed_16_bit(v);
}
}
Notice we set the volume in there to half its maximum level. Anything
over 1.0 would push the value v over 1.0 or less than -1.0 and that
would be clipped when it was mapped to the signed integer.
There are other wave shapes besides sine waves; there are an infinite variety, in fact! Some common computery ones are triangle, sawtooth, and square.
When storing the data, it's often wrapped up in some kind of container with meta-information about the sample rate, number of channels, and so on. (If it's not wrapped up, it's said to be "raw".) One of the most common wrappers for PCM data is the often-used WAV format, which encodes its data in "chunks".
As a demonstration, here is a C program that generates
a WAV file with a sine wave tone in it. Almost all the code
deals with generation of the WAV metadata and little-endian byte
ordering, but the make_data_chunk() function generates the actual
sample data. (If the sound is horrible or anything else fails in the
code, please let me know.)
What about MP3 and Vorbis? How do they store their data? "Very complicatedly," is the answer. They use lossy data compression to greatly reduce the size of their files. If you're playing a CD, it's going through 44,100 samples per second, 2 channels, 16 bits per channel for a total of 172 kilobytes per second, or about 10 megabytes per minute. Lossy compression such as that done by MP3 can easily compress that by a factor of 10 down to 1 megabyte per minute. So they take PCM data, compress it, and store it in their own formats.
For playback, though, it has to do the reverse. The MP3 player will take the MP3 data, decompress it, and do its best to restore it to the original PCM data. Since the compression was lossy, the restoration won't be perfect. But it's more than good enough for virtually everyone, which is why MP3 is so popular.
There are many encoders if you want to convert WAV to MP3, but one popular free one is LAME. Encoders for Vorbis are available on the Vorbis website. The exactly technical details of the conversions are very much beyond the scope of this article.
So there's that. Let's get on to mixing!
The basics of mixing two data sources into one are pretty simple. The problem is that you have, say, two arrays full of audio samples (at the same rate and in the same format), and you want to play them both at once. Perhaps you have two tones and you want to play them together as a chord. Or maybe you have a recording of two politicians and you want them to talk over each other.
What you do is this: add the samples together. Like with addition, or "plus", yes, exactly. You figure out the values for one wave at a particular point in time, and you figure out the values for the other wave at exactly the same point in time, and you add those values together; that's your sample. The two waves summed together make a new funky wave that's highest when the peaks and troughs of the two waves coincide, and is lowest when the two waves cancel each other out.
Click on the buttons below to see and hear it for yourself. This app generates audio, so put on your headphones or do whatever it is you need to do to adequately prepare:
And for those of you who recognize that combined tone, congratulations: you're from North America and you're getting old. Makes you kinda nostalgic, doesn't it?
Here's the code for the sound-generation portion of that Flash piece, basically (I've chopped it down to its bare minimum.)
// This event is triggered when the sound data buffer is
// running dry, and we have to repopulate it.
private function sineGen(event:SampleDataEvent):void {
// how loud we want it (0.0 == mute, 1.0 == max):
var vol:Number = 0.20;
var i:int;
// write 8192 samples, about 0.2 seconds-worth:
for(i = 0; i < 8192; i++) {
// position of our new sample in the whole "stream":
var pos:int = i + event.position;
// angle and amplitude for our 350 Hz tone:
var a1 = 350 * pos*Math.PI*2/44100;
var v1:Number = Math.sin(a1) * vol;
// angle and amplitude for our 440 Hz tone:
var a2:Number = 440 * pos*Math.PI*2/44100;
var v2:Number = Math.sin(a2) * vol;
// add them together
var total:Number = v1 + v2;
// write it out to the stream
event.data.writeFloat(total); // left channel
event.data.writeFloat(total); // same in right channel
}
}
Now I know what you're thinking: did he fire six shots, or only five?
No, probably not. You might be thinking, "But if I take a sample that's at volume 0.8 and add it to another sample that's at 0.9, I'll end up with a result that's 1.7, and that's out of range!" Yes, it is, and it will be clipped down to 1.0 and the data lost, and the sound will be distorted. This is demonstrated when you hit the "Clipped" button in the app, above (when you're adding the two waves together).
You can avoid this by simply scaling down the final volume, or the volumes of the individual samples before mixing.
I used to have a big section here on dynamic range compression, but it was far too incorrect, and I couldn't find a way to demonstrate it to keep it simple, so I took it out. Apologies for those I led astray!