2010-01-13
Recursion
Check out this C code:
void forever(void)
{
forever();
}
Seems straightforward enough. The function calls itself, right? That's recursion—when a function calls itself. In this case, it never stops calling itself. Probably on your implementation, this will eventually cause a callstack overflow and the program will die. (When you make a function call, the return address and function parameters have to be stored somewhere, and often they are stored on a stack. Each time you recursively call a function, more and more return addresses and parameters are pushed on the stack.)
How could we make it stop eventually? What if we made the recursive call conditional on something? Some variable that was passed in, for instance:
void recurse(int c)
{
if (c > 0) {
recurse(c);
}
}
There! Now it calls itself forever if c is greater-than zero, or not
at all otherwise. That's a marginal improvement, but still not useful.
What about this:
recurse(int c)
{
if (c > 0) {
recurse(c - 1);
}
}
Now things are getting interesting! Let's do a run in our heads with
recurse(0). In that case, c is zero, and the function just ends.
What about recurse(1)? In that case, c is 1, which is greater than
zero, so we call recurse(c-1) (which is the same as recurse(0)). On
that call to recurse(), its local variable c is 0. (The outer
call, wherein c is 1 still exists because it hasn't returned yet, but
it's waiting for the inner call to complete.) On the inner call, where
c is zero, the if fails and the function ends, returning to the
outer call where c is one. But the outer call doesn't have anything
to do after that, so it just ends, too. Well, that was a lot of a mess
for a simple call, right? Let's throw a side-effect in there and see
what happens:
void recurse(int c)
{
if (c > 0) {
printf("c is %d\n", c);
recurse(c - 1);
}
}
Now if we run this with recurse(5), look what happens:
c is 5
c is 4
c is 3
c is 2
c is 1
It's a loop! In fact, what we have here is what's called tail recursion. Tail recursion is what you get when you make a recursive call but there's no work to be done after the call (i.e. the call is the last thing in the function).
Tail recursive calls can be trivially replaced with a loop, for example, the above code could simply be written thusly:
void loop_version(int c) { while (c > 0) { printf("c is %d\n", c); c = c - 1; } }This has the advantage of not needing another stack frame for each call, so it can run in constant space. Some languages (especially functional languages) automatically perform this optimization on tail-recursive calls; C generally does not, however.
So what we have here is a complicated way to do a loop—how exciting could that possibly be? Let's take a look again at the example that counts down from 5 to 1. I want you to notice this very important thing: counting down from 5 to 1 is just like printing 5, then counting down from 4 to 1. (See, counting down from 5 to 1 is very similar to counting down from 4 to 1, right? Instead of starting with 5, we start with 4.) So we might phrase the problem like this: "Countdown(N) is defined as 'print N, then Countdown(N-1)'". Ooo! See the recursive definition? And see how it totally matches up with the code that we have written, too!
Sometimes a computing problem is composed of problems identical to itself, and being able to recognize this is important to coming up with a recursive solution. One well-known example that is very commonly used in computer classes is "factorial". For instance, 5-factorial, written "5!" is the same as 5×4×3×2×1. And 4! is 4×3×2×1. And now you see how 5! is the same as 5×4!, yes? Generally, n! = n×(n-1)! Every (again, generally) factorial operation is composed of another factorial operation similar to itself—it's turtles all the way down!
Let's take a stab at it in C:
int factorial(int n)
{
return n * factorial(n - 1); // < -- here's our "n! = n * (n-1)!"
}
It's close, but not quite; you've probably noticed that it calls itself
forever and there's no conditional in there to ever make it stop. We
should add one! The terminal condition for the recursive function is
referred to as the base
case.
What is the base case for the factorial function? Well, as we count
down from the starting value of n, n eventually gets to zero (and
after that, it goes negative). What is zero factorial? It turns out, 0!
is defined as 1, so we'd better take that into account, and it makes a
great base case.
int factorial(int n)
{
if (n == 0) {
return 1;
}
return n * factorial(n - 1); // < -- here's our "n! = n * (n-1)!"
}
And there we go! It calculates factorials for us.
Now, is that tail recursion? After all, the call to factorial()
happens at the end of the function, right? Actually in this case, it
doesn't! The multiply still must take place after the call, so the call
is not, in fact, the last thing to happen in the function. So it is
not tail recursion.
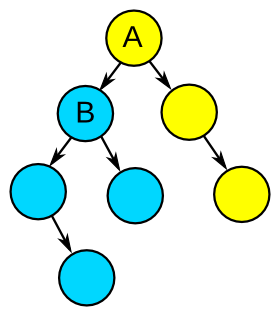 A tree with root node "A", containing a
subtree with root node "B".
A tree with root node "A", containing a
subtree with root node "B".
Another way of thinking about it is that each time factorial() is
called with parameter n, it's going to remain there on the last line
of the function waiting for the recursive call to factorial() to
return. It has to wait, so that it has the result to multiply by n.
In a way, the function is using the call stack to "remember" where it
was in the factorial process so it could come back to it later.
Another common problem in computer science involves traversing tree structures. Again, you look for the self-similar nature of the problem and its subproblems, and, if you can find it, then you can apply recursion to the subproblem. For example, in the image to the right, there is a binary tree with root node "A", which contains a node "B". But notice that you could imagine that "B" is the root of its own subtree. That's the self-similar structure to which recursion can be applied. So a possible way to traverse the tree would be "Traverse(Node) is defined as: Process Node, then Traverse(Node's_Left_Child) and Traverse(Node's_Right_Child)" then you run "Traverse(A)" to start the traverse at the root of the tree.
Actually, when traversing trees like this, you can choose to process the current node before processing the child nodes. Or you can process the left child, then the current node, then the right child. Or you can process the children first, then process the current node. These modes of traversal are known as "pre-order", "in-order", and "post-order" traversals, respectively, and each produces different results.
But lets leave the math and trees behind for a little bit, and look at another slightly more fun algorithm: one for flood fill.
 A bitmap; the one of the right has
had its outer area flood-filled with yellow pixels. The flood could not
break through the wall of blue pixels.
A bitmap; the one of the right has
had its outer area flood-filled with yellow pixels. The flood could not
break through the wall of blue pixels.
Flood-filling is when you take an arbitrary bounded area, e.g. an empty area on a bitmap, and you fill it up to its edges with a different value, e.g. with a different color. The trick is that the area to be filled can abut all kinds of weird arbitrary shapes, so it's not as simple as just filling a rectangle with a certain color. Furthermore, the flood fill will fill the arbitrarily-bounded area, no matter where in the area is was initiated. That is, in the example bitmap to the right, any of the yellow pixels could have been chosen as the starting point for the yellow flood fill. (If a white pixel on the inner portion of the blue shape had been chosen, only the inner portion of the shape would have been filled.) How can we apply recursive thinking to this problem?
Just like we took a step back with the tree and looked at it from each node's perspective (thus forming a lot of small trees inside the main tree), let's take a step back and view the flood fill from a closeup perspective: that of the pixel. When we start the flood at a certain pixel, we want to color that pixel with the fill color.... and then what? Well, what about that pixel's neighbors? Don't we want to color them with the fill color, too? And what about the neighbor's neighbors? So let's do this: "define FloodFill(pixel) to be: set pixel's color to the fill color, then FloodFill(pixel's neighbors)".
What this means is that for each pixel, if it's north neighbor is empty, then FloodFill(North_Neighbor). And if it's west neighbor is empty, then FloodFill(West_Neighbor). And the same for south and east. One option here is to only flood fill, say, West, if the West_Neighbor is empty; another option is to always flood fill West, and let that pixel simply "return" if it already has something in it—this latter method is a base case that gives slightly cleaner code (fewer if-conditions).
When we run a flood fill like this, what it will do is begin at the
first pixel, and then will immediately head off to the next pixel,
without having finished the first one yet. For example, it might head
off to the east from the first pixel, but it hasn't headed off to the
south yet from the first pixel. But that's ok, because eventually, as
the recursive calls finish up and unwind, it'll get back to the first
pixel and then go south from there. It is using the call stack to
"remember" where it still needs to explore, just like the factorial()
function was using the call stack to remember where in the calculation
it was.
Here's a little demonstration. In the following applet, you can draw blue "wall" pixels, then select the "Flood!" tool and click on an empty cell to begin the flood. While the flood is occurring, orange pixels indicate pixels which still have directions remaining to check (i.e. those pixels haven't tried all their neighbors yet, and are still on the stack), while yellow pixels are complete (that portion of the bitmap is completely flooded and all neighbors flood-filled, and those pixels are popped off the stack.) Or, put another way, orange appears as pixels are pushed on the stack, and yellow appears as they are popped off.
Be advised that this is probably not the best way to do a flood fill (in terms of processing time and memory consumption), but it does demonstrate recursion quite nicely!
As you can see, recursion slices and dices a variety of different problems, but all these problems have one thing in common: they can all be broken down into self-similar sub-problems, each of which can be worked in the same way as the whole.
For a fun side-adventure with the above applet, draw a complicated maze and then start flood-filling from one far corner of the maze. Does it find its way out?
In parting, I'd like you to do the following thought experiment:
-
Take a set of numbers, S.
-
Pull the first number from S, and call it p.
-
Construct two more sets, T and U, where T is all the numbers in S that are less than p, and U is all the numbers in S that are greater than p.
-
Notice that if you make a new set of numbers, V, where V is the concatenation of T + p + U, that p is in its final resting place if you were to sort the entire set S. It has to be the final resting place, because everything less than p is on its left in set T, and everything greater than p is on its right in U. As such, that one number p is "sorted", but sets T and U remain to be sorted. Now very importantly notice the self-similarity between sets T, U, and the set we just did, S. Can we just run steps 1-4 on T and U and produce another "sorted" number each time we run those steps? Yes, we can!
-
So keep repeating steps 1-4 on the resultant sets T and U until those sets contain fewer than two elements. Then stop.
You've just done the famous Quicksort! Woo hoo!
And if you liked this article, you might also enjoy my article on recursion.